Model Overview
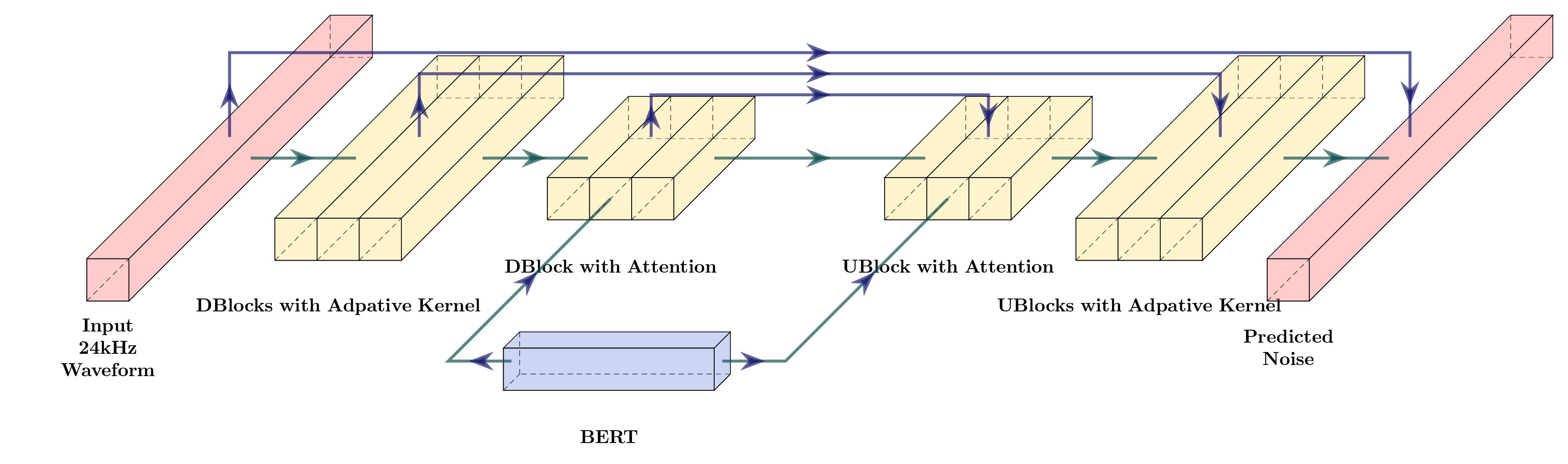
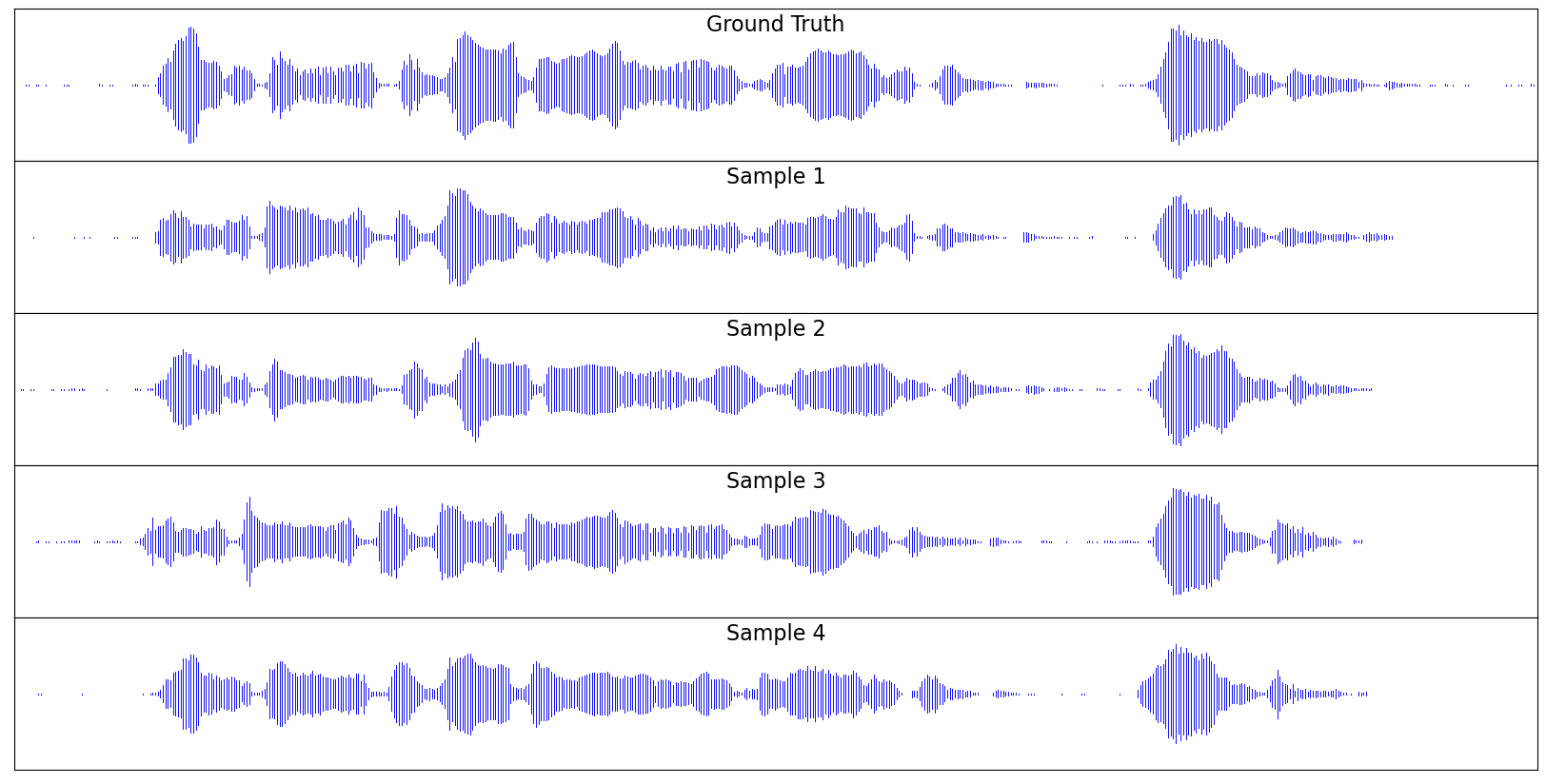
To take advantage of recent advances in large language model development, we built our system on top of a pre-trained BERT model. The BERT model takes subword input and does not rely on any other representations of speech, such as phonemes or graphemes. Then it is followed by a 1D U-Net structure, which consists of a series of downsampling and upsampling blocks connected by residual connections. The entire model is non-autoregressive and directly outputs a waveform. The speaker and alignment are dynamically determined during the diffusion process. Our model achieves comparable results to the two-stage framework on a proprietary dataset.